Lacto Fermented Red Jalapeños
This turned out really well in the end, but I can’t find the notes, only some pictures taken during the process. I recall the original plan was to bring this and some onions to the upcoming 4th of July. I have a photo of it fully prepared and jarred on July 6, and was away by July 3, so processing is estimated at July 2 at the latest.
Fermentation was started , at about 3PM. Thus total fermenting time was rather short, only about 10 days.
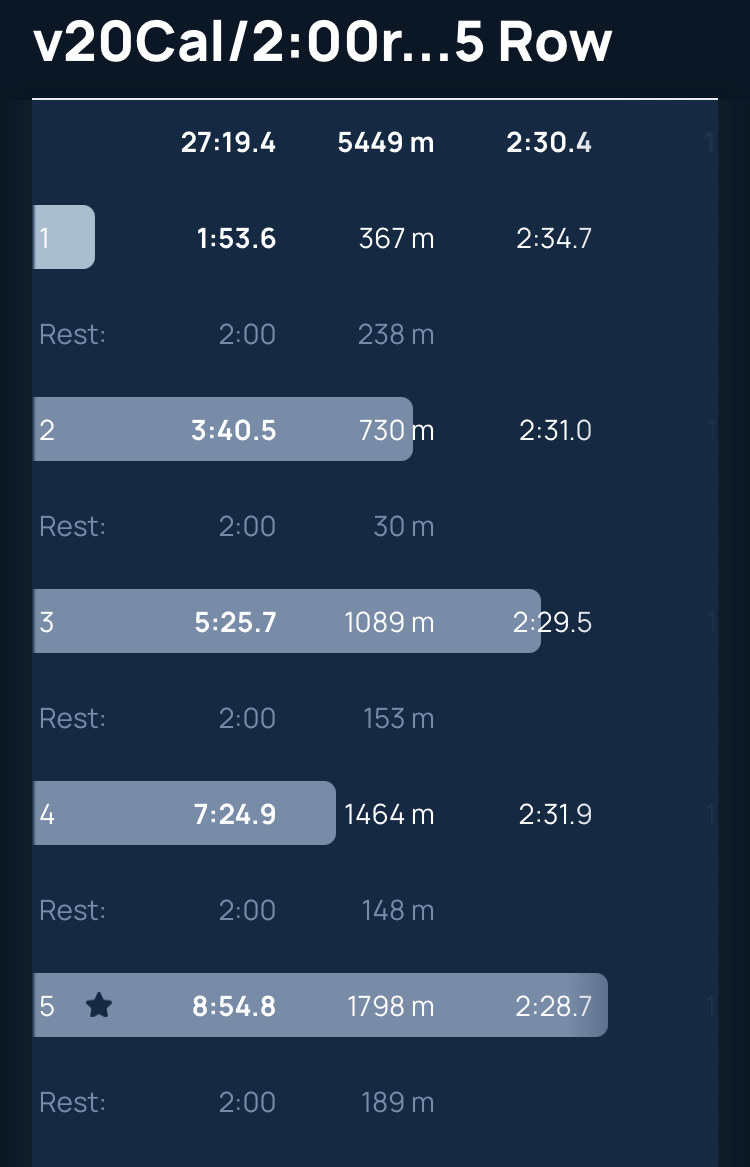
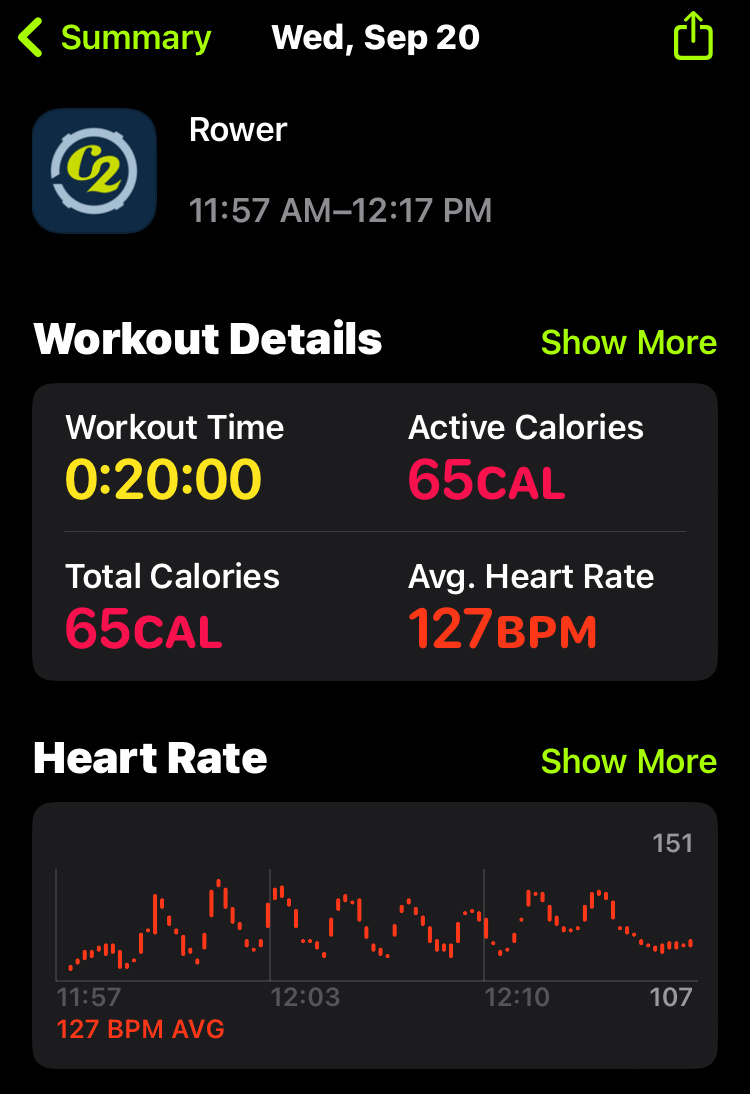
September 21, 2023 - c2 wod - increasing 20 calorie intervals
Concept2 Workout of the day
Five “calorie intervals”. First interval - 20 cals. Second interval 40 cals. Then 60, 80 and 100. Two minutes at light pressure between each piece.
This was a more cardio focused for me.
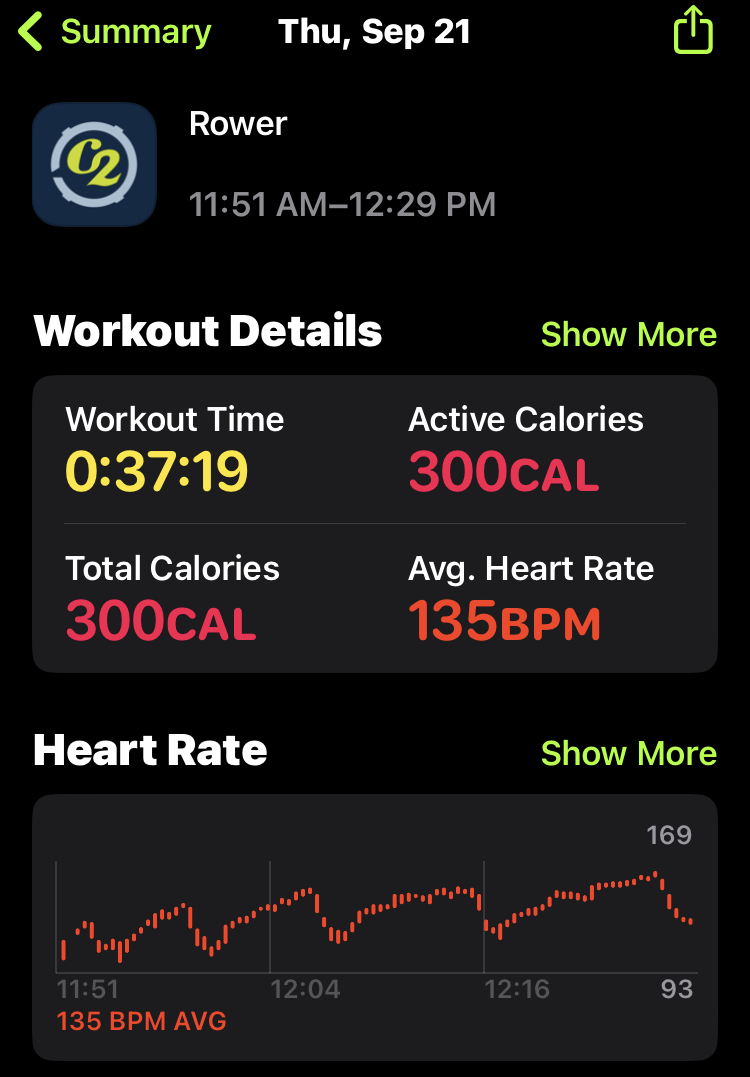
Intervals were pretty even, probably should have gone harder in the beginning.